项目概述
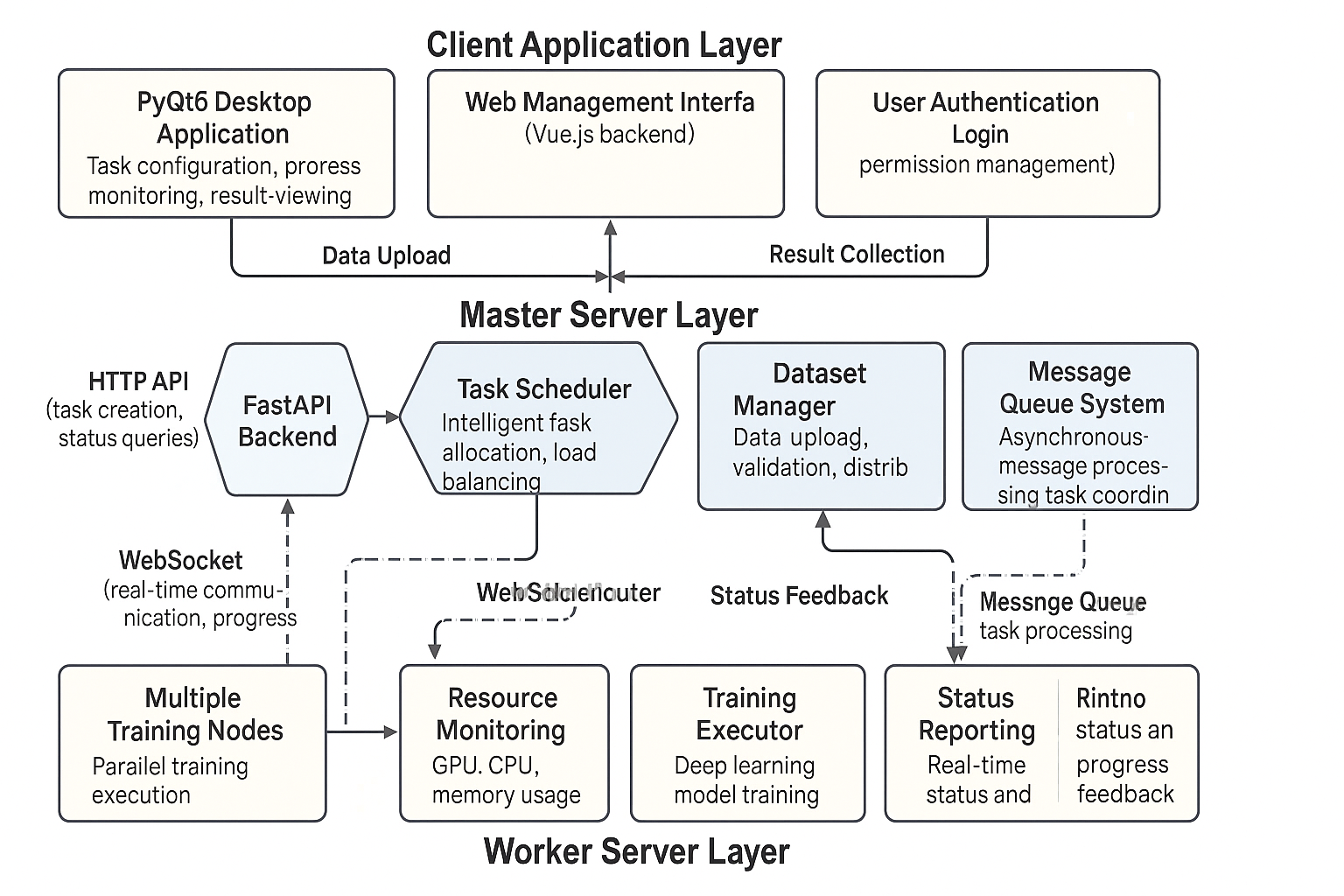
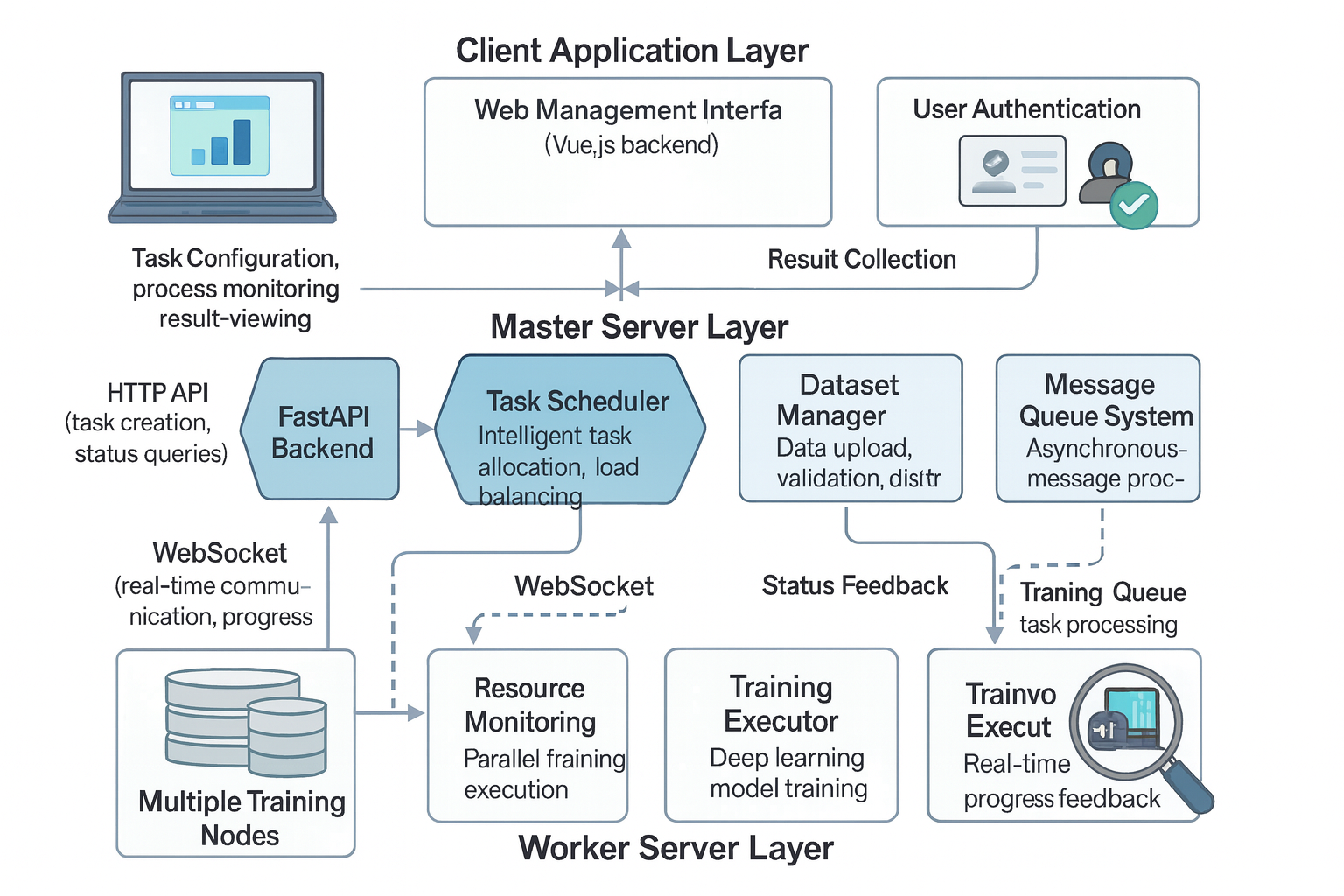
TrainSphere是一个专为大规模深度学习训练设计的分布式训练平台,采用主从架构和智能负载均衡技术,能够有效协调多个训练服务器,显著提升模型训练效率。
该系统解决了传统单机训练在计算资源、训练时间和扩展性方面的限制,通过分布式任务调度、实时通信和智能资源管理,实现了训练效率的显著提升。
🎯 核心价值
TrainSphere通过分布式架构和智能优化,相比单机训练实现了300%的效率提升,为大规模AI模型训练提供了可靠的技术基础设施。
核心功能
分布式任务调度
系统采用智能任务调度算法,能够根据各节点的计算能力、内存状态和网络状况,动态分配训练任务。支持任务优先级设置、资源预留和抢占式调度。
实时通信与同步
基于WebSocket的实时通信机制,确保主节点能够及时获取各训练节点的状态信息,实现训练进度的实时监控和同步。支持断线重连和消息重传。
智能负载均衡
动态负载均衡算法能够实时监控各节点的资源使用情况,自动调整任务分配策略,确保系统整体资源利用率最大化,避免单点过载。
故障检测与恢复
完善的故障检测机制,能够快速识别节点故障、网络异常等问题,并自动进行任务重新分配和故障恢复,确保训练任务的连续性。
应用场景
大规模模型训练
适用于需要大量计算资源的深度学习模型训练,如大型语言模型、计算机视觉模型、推荐系统等。通过分布式训练,能够显著缩短训练时间。
企业AI基础设施
为企业提供完整的AI训练基础设施,支持多团队、多项目的并行开发,提高AI研发效率,降低硬件投入成本。
科研实验平台
为科研机构提供灵活的分布式训练平台,支持各种深度学习框架和算法,加速AI技术研究和创新。
云原生AI服务
支持容器化部署和云原生架构,能够快速部署到各种云平台,提供弹性扩展的AI训练服务。